Russell Coker: Process Monitoring
Since forking the Mon project to etbemon [1] I ve been spending a lot of time working on the monitor scripts. Actually monitoring something is usually quite easy, deciding what to monitor tends to be the hard part. The process monitoring script ps.monitor is the one I m about to redesign.
Here are some of my ideas for monitoring processes. Please comment if you have any suggestions for how do do things better.
For people who don t use mon, the monitor scripts return 0 if everything is OK and 1 if there s a problem along with using stdout to display an error message. While I m not aware of anyone hooking mon scripts into a different monitoring system that s going to be easy to do. One thing I plan to work on in the future is interoperability between mon and other systems such as Nagios.
Basic Monitoring
ps.monitor tor:1-1 master:1-2 auditd:1-1 cron:1-5 rsyslogd:1-1 dbus-daemon:1- sshd:1- watchdog:1-2I m currently planning some sort of rewrite of the process monitoring script. The current functionality is to have a list of process names on the command line with minimum and maximum numbers for the instances of the process in question. The above is a sample of the configuration of the monitor. There are some limitations to this, the master process in this instance refers to the main process of Postfix, but other daemons use the same process name (it s one of those names that s wrong because it s so obvious). One obvious solution to this is to give the option of specifying the full path so that /usr/lib/postfix/sbin/master can be differentiated from all the other programs named master. The next issue is processes that may run on behalf of multiple users. With sshd there is a single process to accept new connections running as root and a process running under the UID of each logged in user. So the number of sshd processes running as root will be one greater than the number of root login sessions. This means that if a sysadmin logs in directly as root via ssh (which is controversial and not the topic of this post merely something that people do which I have to support) and the master process then crashes (or the sysadmin stops it either accidentally or deliberately) there won t be an alert about the missing process. Of course the correct thing to do is to have a monitor talk to port 22 and look for the string SSH-2.0-OpenSSH_ . Sometimes there are multiple instances of a daemon running under different UIDs that need to be monitored separately. So obviously we need the ability to monitor processes by UID. In many cases process monitoring can be replaced by monitoring of service ports. So if something is listening on port 25 then it probably means that the Postfix master process is running regardless of what other master processes there are. But for my use I find it handy to have multiple monitors, if I get a Jabber message about being unable to send mail to a server immediately followed by a Jabber message from that server saying that master isn t running I don t need to fully wake up to know where the problem is. SE Linux One feature that I want is monitoring SE Linux contexts of processes in the same way as monitoring UIDs. While I m not interested in writing tests for other security systems I would be happy to include code that other people write. So whatever I do I want to make it flexible enough to work with multiple security systems. Transient Processes Most daemons have a second process of the same name running during the startup process. This means if you monitor for exactly 1 instance of a process you may get an alert about 2 processes running when logrotate or something similar restarts the daemon. Also you may get an alert about 0 instances if the check happens to run at exactly the wrong time during the restart. My current way of dealing with this on my servers is to not alert until the second failure event with the alertafter 2 directive. The failure_interval directive allows specifying the time between checks when the monitor is in a failed state, setting that to a low value means that waiting for a second failure result doesn t delay the notification much. To deal with this I ve been thinking of making the ps.monitor script automatically check again after a specified delay. I think that solving the problem with a single parameter to the monitor script is better than using 2 configuration directives to mon to work around it. CPU Use Mon currently has a loadavg.monitor script that to check the load average. But that won t catch the case of a single process using too much CPU time but not enough to raise the system load average. Also it won t catch the case of a CPU hungry process going quiet (EG when the SETI at Home server goes down) while another process goes into an infinite loop. One way of addressing this would be to have the ps.monitor script have yet another configuration option to monitor CPU use, but this might get confusing. Another option would be to have a separate script that alerts on any process that uses more than a specified percentage of CPU time over it s lifetime or over the last few seconds unless it s in a whitelist of processes and users who are exempt from such checks. Probably every regular user would be exempt from such checks because you never know when they will run a file compression program. Also there is a short list of daemons that are excluded (like BOINC) and system processes (like gzip which is run from several cron jobs). Monitoring for Exclusion A common programming mistake is to call setuid() before setgid() which means that the program doesn t have permission to call setgid(). If return codes aren t checked (and people who make such rookie mistakes tend not to check return codes) then the process keeps elevated permissions. Checking for processes running as GID 0 but not UID 0 would be handy. As an aside a quick examination of a Debian/Testing workstation didn t show any obvious way that a process with GID 0 could gain elevated privileges, but that could change with one chmod 770 command. On a SE Linux system there should be only one process running with the domain init_t. Currently that doesn t happen in Stretch systems running daemons such as mysqld and tor due to policy not matching the recent functionality of systemd as requested by daemon service files. Such issues will keep occurring so we need automated tests for them. Automated tests for configuration errors that might impact system security is a bigger issue, I ll probably write a separate blog post about it.
 Update Some youtube links are not viewable or even seen on planet.debian.org. Seems p.d.o. tries its best to remove external links, sorry for the breakage.
Beware some youtube-links would be shared in this entry, sorry couldn t find a better/easier media platform to work with. If anyone knows any other platform or wants to suggest, feel free to either mail me or let me know in comments.
I want to start today s sharing with a picture of Ganesha I saw today. It is and was public art hence sharing it without an issue.
Update Some youtube links are not viewable or even seen on planet.debian.org. Seems p.d.o. tries its best to remove external links, sorry for the breakage.
Beware some youtube-links would be shared in this entry, sorry couldn t find a better/easier media platform to work with. If anyone knows any other platform or wants to suggest, feel free to either mail me or let me know in comments.
I want to start today s sharing with a picture of Ganesha I saw today. It is and was public art hence sharing it without an issue.
 This is starting of festivities time in India and Ganesha or Ganpati is looked up as a good omen in India.
The festival of Ganesh Chaturthi would be starting on the 25th of August and is a sight to behold. Just like Rio has its carnival, Ganesh Chaturthi is also a carnival. We also have parades where people come with Pandals (or temporary structures)
The mythology says he has a sweet tooth (hence lot of distribution of sweets, especially modak) and anything which might be troubling people, he creates solutions for them.
Here is one video of how people celebrate his immersion in India. This is from my home-town few years ago, every year the madness and the celebrations are becoming more and more. People from far off come to see how we celebrate and see how different people make their Pandals. While some are with music, others are with social messages. Usually people start going to see these structures after dusk and return home way after midnight or early morning. I hope to do this endeavour after many years. One is drunk from hearing all sorts of different kids of music, decoration, messages, a feast and a strain to all the senses.
Ganesha immersion celebrations
This is starting of festivities time in India and Ganesha or Ganpati is looked up as a good omen in India.
The festival of Ganesh Chaturthi would be starting on the 25th of August and is a sight to behold. Just like Rio has its carnival, Ganesh Chaturthi is also a carnival. We also have parades where people come with Pandals (or temporary structures)
The mythology says he has a sweet tooth (hence lot of distribution of sweets, especially modak) and anything which might be troubling people, he creates solutions for them.
Here is one video of how people celebrate his immersion in India. This is from my home-town few years ago, every year the madness and the celebrations are becoming more and more. People from far off come to see how we celebrate and see how different people make their Pandals. While some are with music, others are with social messages. Usually people start going to see these structures after dusk and return home way after midnight or early morning. I hope to do this endeavour after many years. One is drunk from hearing all sorts of different kids of music, decoration, messages, a feast and a strain to all the senses.
Ganesha immersion celebrations  Anyways, the above song is what would be called a perfect Sufi song. I hope people enjoy the longing and the silence which follows this piece.
Another classic one
4.
Lyrical song
Anyways, the above song is what would be called a perfect Sufi song. I hope people enjoy the longing and the silence which follows this piece.
Another classic one
4.
Lyrical song 






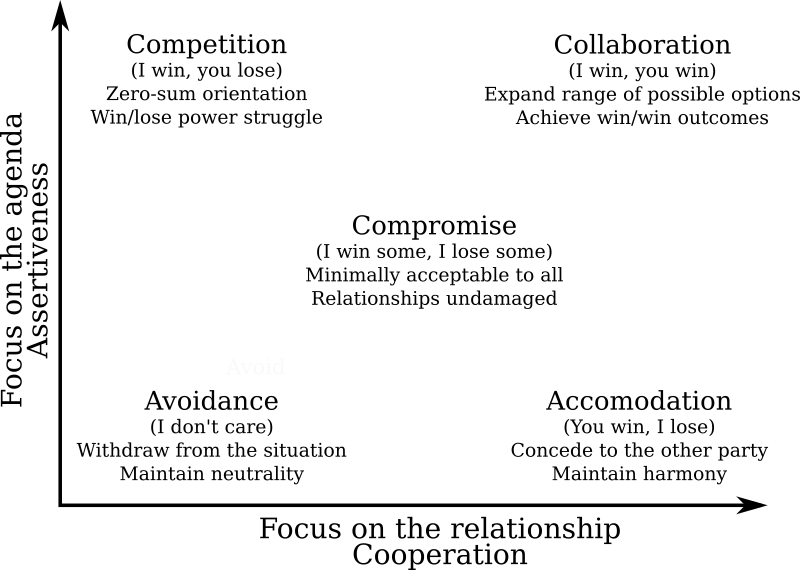 The
The  Earlier today, I demonstrated how to work with
Earlier today, I demonstrated how to work with  A fair amount of things happened since I last blogged something else than music. First of all we did actually hold a
A fair amount of things happened since I last blogged something else than music. First of all we did actually hold a  In this scenario, instead of doing the traditional transfer from
Netfilter's TPROXY to user space, the kernel directly decapsulates the
HTTP traffic and passes it to BPF rules that can make decisions without
doing expensive context switches or memory copies in the case of simply
wanting to refuse traffic (e.g. issue an HTTP 403 error). This, of
course, requires the
In this scenario, instead of doing the traditional transfer from
Netfilter's TPROXY to user space, the kernel directly decapsulates the
HTTP traffic and passes it to BPF rules that can make decisions without
doing expensive context switches or memory copies in the case of simply
wanting to refuse traffic (e.g. issue an HTTP 403 error). This, of
course, requires the 

 or for that matter any part of the body. If more people thought like that, probably we wouldn t have to specially grow and then kill lab mice and guinea-pigs to test out theories. Possibly medical innovations would probably be a lot faster than now. Ironically, most medical innovations have happened during
or for that matter any part of the body. If more people thought like that, probably we wouldn t have to specially grow and then kill lab mice and guinea-pigs to test out theories. Possibly medical innovations would probably be a lot faster than now. Ironically, most medical innovations have happened during 








 So much for my monthly blogging! Here s what I have been up to in the Open Source world over the last 6 months.
Debian
So much for my monthly blogging! Here s what I have been up to in the Open Source world over the last 6 months.
Debian



{kind=link}
{kind=link}
{kind=link}
{kind=link}
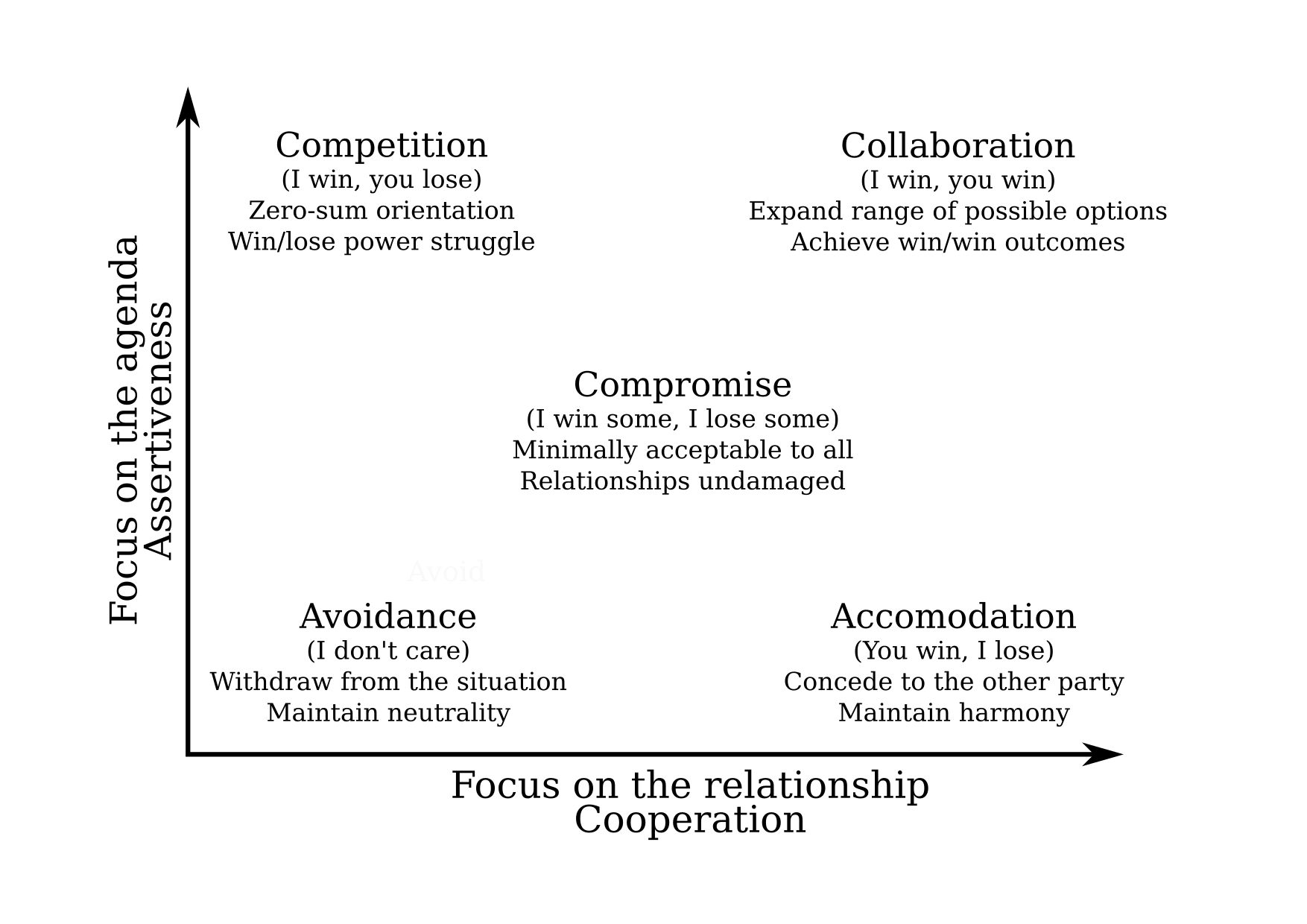{kind=link}
{kind=link}
{kind=link}